Remote Relay
In my previous blog post I started my mission of "stupid dumb fun" coding. The first project I chose was doing fun stuff with a Raspberry Pi and the Combusion thermometer probe. At the end of that blog post I had a simple Rust program which could discover the Combustion probe over bluetooth and pull the latest temperature off the tip of the probe as well as a Python program which would display the latest temperature on a tiny screen attached to the Pi.
At the end of that blog post I threw out some ideas for my next project and I quickly settled on a remote relay. One of the most common use-cases I can think for this will be smoking meats in my backyard. With my old bluetooth thermometer I could connect to it with my phone pretty much only if I was within eyesight; this is a bit of a problem when I want to sit in my living room.
Goal Setting
I wanted to start with a very basic flow:
- Start cooking good foods and set up the thermometer target temperature with my phone app.
- Plug in Raspberry Pi at the back of my house overlooking the yard.
- View temperature on my phone from anywhere I have internet.
Architecture
This led to a pretty simple architecture just to start:
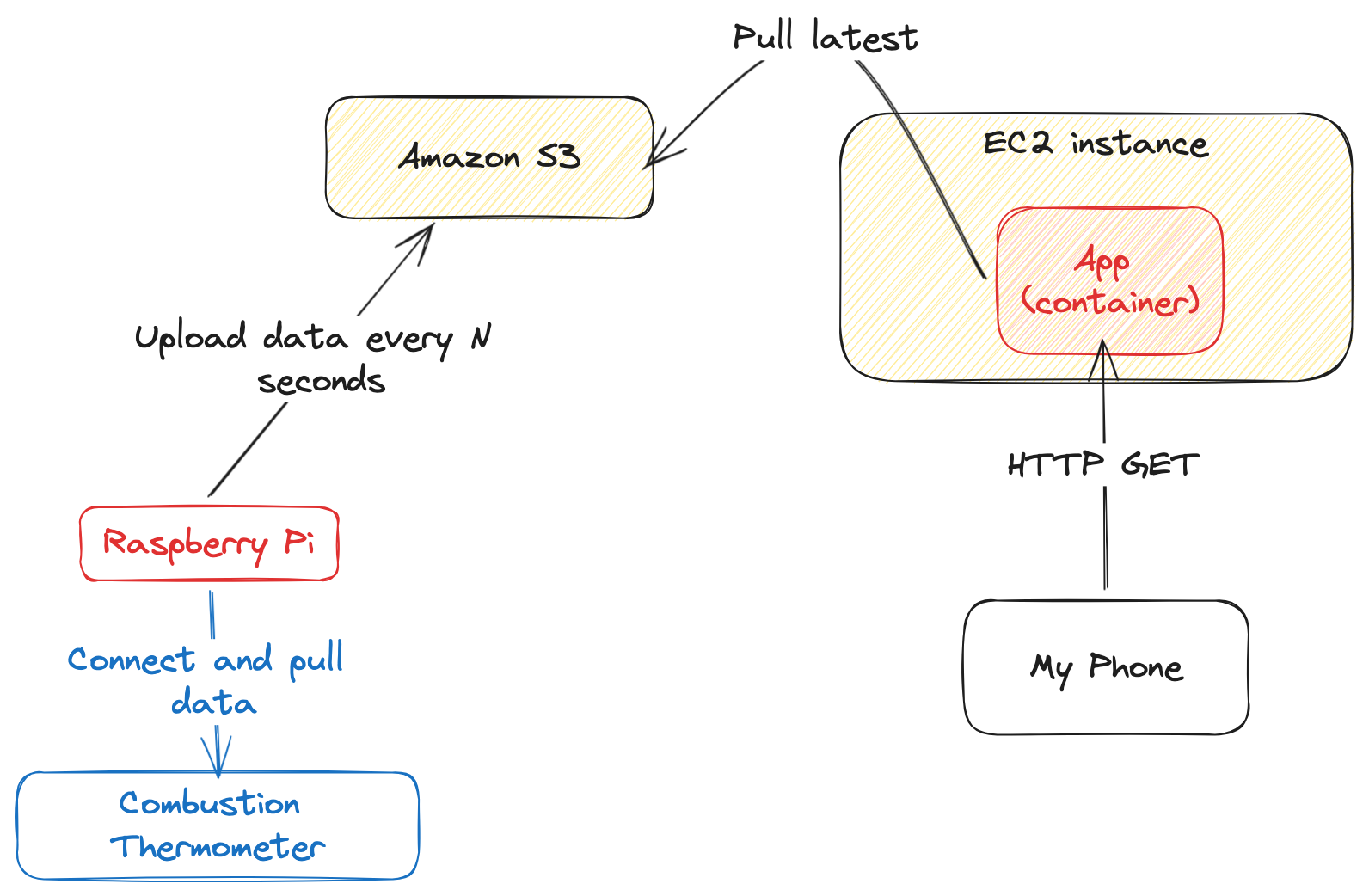
- The Raspberry Pi connects to the Combustion
- It pulls the latest data every N seconds and uploads every X seconds (N and X to be fiddled with constantly)
- The S3 key should be unique per cooking "session" which for now can be every time the process starts. Ended up using the RFC3339 date time at process start.
- The web service shows some HTML page whenever I load it with the latest temperature
- The web service should be as cheap as possible because this isn't work and it comes out of my pocket.
Mac Dev
You can see everything I did in this PR on github.
While getting the Raspberry Pi up and running has been fun, it's slow as hell to develop on. That could be because I'm using a 16GB SD card which is running at the edge of its capacity (Rust dependencies seem to take up a ton of space) or because it's underpowered, but one of the first things I wanted to do was code on my Mac.
The Rust crate I'm using (bluer) won't compile on Mac because it depends on a DBus crate which links to the DBus system libraries which don't exist on Macs! Bluez is the official Linux bluetooth stack, and DBus is used for communicating between Linux daemons - this won't work for Mac dev.
Therefore I needed to write some implementation that I could compile and run on my Mac dev laptop for when I don't feel like running the Raspberry Pi (eg: when I'm on the couch downstairs). This could be a dummy program that generates some data and uploads it to S3 in the expected format.
Modularizing
The obvious thing (to me) would be to write some type class (or an interface in Go, which is what I write in my day job) that either the Mac or Linux versions could implement. But that still comes across the issue that I can't compile the DBus/Bluer libraries on the Mac!
I worked around this issue by using conditional compilation. In Rust files you can write
#[cfg(target_os="linux")]
mod mymod {
...
}
And mymod will only compile/be available on OSes other than Linux.
I went through a few phases of refactoring, but it generally broke into two phases:
Github commit. The first was to just get it working by writing two modules named the same thing but with conditional compilation only for linux and macos. I just had two modules named combustion in the same file with the conditional compilation flags above each. (Side note: it occurs to me the MacOS module should just be "not linux". Willfix).
I wrapped my previous code interfacing with the Bluetooth library behind two structs:
pub struct CombustionFinder {
...
}
impl CombustionFinder {
pub async fn new() -> anyhow::Result<CombustionFinder> {
...
}
pub async fn discover(&self, mut done: &mut Receiver<bool>) -> anyhow::Result<Combustion> {
...
}
}
pub struct Combustion {
...
}
impl Combustion {
pub fn new() -> Combustion {
Combustion {
...
}
}
pub async fn connect(&mut self) -> anyhow::Result<()> {
...
}
pub async fn get_raw_temp(&self) -> anyhow::Result<Option<f32>> {
...
}
pub async fn disconnect(&self) -> anyhow::Result<()> {
...
}
}
I went with a CombustionFinder which (in the Linux version) creates the bluer::Session and gets the session.default_adapter(). It has one async function to discover the device which is expected to run and keep scanning the ether until either it returns the device or an error. I'm using the anyhow library which is super easy to use. I think in a binary program it makes things super easy--I don't know if I'd use it if I was publishing a crate, but in the end application it's super useful.
The device is a Combustion struct. This can connect to the device (verifying the device in the process), it can get_raw_temp to do exactly that, and it can disconnect which is self explanatory.
The Linux implementation is just the code from my last blog post adapted into the struct. The initial Mac implementation just returned a static value stored in the Combustion struct.
Checking my work
Another tricky thing was how make the dependency available only on Linux. It's not my code that has the problem, it's theirs (bluez/dbus). For that I modified the Cargo.toml file (removing the dependencies from the main section).
[target.'cfg(target_os = "linux")'.dependencies]
bluer = { version = "0.16.1", features = ["full"] }
modular-bitfield = "0.11.2"
I don't know why, but that took me literally ages to figure out. It seems fairly obvious in the Cargo specification but I guess it wasn't working for me for some reason. But I figured it out eventually.
Once I got it working on my Mac I had to make sure it would work in Linux too. For that I created a Dockerfile.
FROM debian:latest
RUN apt-get update
RUN apt-get install gcc xz-utils wget curl -y
RUN apt-get install libdbus-1-dev libglib2.0-dev libudev-dev libical-dev libreadline-dev -y
WORKDIR "/tmp"
RUN wget https://mirrors.edge.kernel.org/pub/linux/bluetooth/bluez-5.69.tar.xz
RUN tar xf bluez-5.69.tar.xz
WORKDIR "/tmp/bluez-5.69"
RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | bash -s -- -y
RUN echo 'source $HOME/.cargo/env' >> $HOME/.bashrc
VOLUME /rustbustion
WORKDIR "/"
# udev issue
CMD ["echo", "hello world"]
It's pretty simple. I haven't looked at this in a while, I guess what I wanted to do with the echo "hello world" as the entry command is because I was mostly using it by docker run <imageid> --rm --it /bin/bash and then compiling the code within the created docker container. It took a while to figure out all of the dependencies and get them installed, but once I did I was able to successfully compile the app! Trying to run it obviously failed; while the bluetooth library might exist on the Debian container running virtualized on my Mac I don't think VirtualBox understands how to translate from the Linux OS bluetooth service to my Mac bluetooth interface. Maybe someone has figured that out, I really didn't care.
Eventually I did figure out how to move the Linux/Mac code into their own files fairly elegantly in this commit.
S3 Bucket Creation and Pushing
Infrastructure Management
Like I said I wanted this to be dead simple and created with technologies I understand. I'm not trying to learn a whole bunch of things (although that might come naturally), I just want to get the damn thing working.
So with that said I reached for my personal preferred infrastructure as code library: Amazon CDK. Reader, I cannot tell you how much this has improved cloud software development life at Amazon. Pre-CDK managing our infrastructure was with CloudFormation and our deployment infrastructure was with Ruby scripts (ew). Now it's all Typescript which has documentation, and types, and documentation! and types!
CDK Aside
I like CloudFormation a lot, more than terraform. I like the idea of deploying a Stack in AWS that presumably has an understanding of the state of my infrastructure so that I can apply a change and have it figure out both how to mutate the infrastructure to get to that state AND MOST IMPORTANTLY if something fails how to mutate the infrastructure back (mostly) safely.
Terraform is great but it feels like a big foot-gun where it can fail and I don't know the state of things. I've also had less-than-stellar experiences working on a single Terraform codebase with multiple other developers. I'm sure organizations can do it successfully, I haven't experienced that.
Ok we're back
The thing is that even though I like CDK as a concept, I don't want to write a whole lot of it in my free time. Instead I turned to my good friend ChatGPT. I sent just a few terse chats to it:
Me: CDK code to create: an S3 bucket, an EC2 instance with an IAM role that allows it to read from the S3 bucket, and an IAM user
ChatGPT: (formally polite response with all of the code I requested)
Me: Add ability to pass a variable over the command line which is used as the bucket name
ChatGPT: (does it)
Me: If bucket name is not provided then exit with an error
ChatGPT: (does it)
I freaking love ChatGPT. These were literally my messages to it, I don't need any bullshit prompt engineering techniques. I just "give thing" and it figures out thing. Hell, I could probably say "giv thgn" and it would figure it out. It's great as hell for side projects where I know what I want to do, I just don't want to spend too much brain power on it.
This gave me just a typescript file, after this I still had to set up CDK on my dev laptop, create a new CDK project, and import the file into it. So I had to open up vim for a little bit. But it was fairly easy.
The CDK does what I said to ChatGPT: it creates a bucket that I can define with a value on the command line (I also suffixed it with -combustion because S3 buckets need to be globally unique I believe), an EC2 instance with an instance role that can pull from the bucket, and an IAM user that can access the bucket which will be used by the Raspberry Pi.
For local AWS credentials I created an access key/secret for my root user (usually don't do this but it's my laptop) and put those creds under a profile in ~/.aws/credentials. First you bootstrap your AWS account for CDK and then you deploy your CDK code:
$ cdk --profile=<me> bootstrap --context name="myname"
$ cdk --profile=<me> deploy --context name="myname"
Whenever you make CDK changes, then you cdk --profile=<me> deploy --context name="myname" again.
Rust Pusher
After I set this infrastructure up I decided to go back to the Rust Raspberry Pi binary to push some example values to S3. This is the commit here.
Note on Async Code Style
A note on my preferred software "style" for coding async programs which comes from a lot of Go development. I prefer to write as much synchronous code as possible and then "launch" the synchronous code in async tasks that can communicate through channels. I tend to see a lot of more junior or async-inexperienced engineers write a lot of code that launches tasks/Goroutines behind a "Start" function. While that's fine I think it makes programs harder to reason about:
How do you stop what was started? You could provide a context (Go) or a channel that denotes "doneness". Does Start need to be idempotent? Will everyone make sure to write it that way with the right assumptions? Will people remember to Stop things?
How this manifests in my Rustbustion code is to have a main function that looks like this pseudo-Rust-code with no real error handling:
#[tokio::main(flavor = "current_thread")]
async fn main() -> anyhow::Result<()> {
let finder = CombustionFinder::new();
let device = finder.find().await?;
device.connect().await?;
let (temperature_tx, mut temperature_rx) = tokio::sync::mpsc::channel(100);
let pusher = Pusher::new("bucket-name");
tokio::spawn(async move {
while let Some(t) = temperature_rx.recv().await {
if let Err(e) = pusher.push(t) {
error!("There was a pushing error: {:?}", e);
continue;
}
}
});
loop {
let mut interval = tokio::time::interval(tokio::time::Duration::from_millis(5000));
let mut i = 0;
tokio::select! {
_ = interval.tick() => {
let t = device.get_raw_temp().await?;
temperature_tx.send(t);
}
// Done signaling
}
}
Ok(())
}
Pusher has one synchronous-looking function called push and the Combustion struct has one synchronous-looking function called get_raw_temp. The main function spawns a Tokio task to wait for temperatures coming over a channel and pushes them on to S3 (which the Pusher encapsulates). It then loops forever getting temperatures on a ticker and pushing them into the channel; once there's some cancellation signal (eg: Ctrl-C) it exits the loop.
The local server that the Python server reads from uses an Arc<Mutex<f32>> because the server just needs to serve the latest value. Ultimately the server (which uses Warp) would need an Arc<Mutex<f32>> pattern somewhere I would assume because the Svc struct used by Warp would need thread-safety. Without looking at any documentation, if I want any request to my HTTP server to access the latest value written by (likely) another system thread, I need memory safety.
Another note to self: I need to wait for the S3 pusher to be done and handle any backlog. In Go I'd use a sync.WaitGroup for that. I'm sure there's something in Rust for this.
Actual S3 Pushing code
The actual S3 code is boring. Here's the commit. It's pretty much just all about figuring out when the rollover is in the buffer that I defined (100 entries) and forming the S3 key structure.
To test the S3 abilities what I did was I made an IAM User with the right credentials and got an access key/secret for it. I put that under a profile in ~/.aws/credentials and ran my Rust code to see that it all worked on my Mac. I did the same thing on my Raspberry Pi before calling it good.
Wrapping Up
I think this blog post is getting long so I'm going to wrap it up here!
At this point in my little project I have some CDK code which sets up an S3 bucket and a simple EC2 instance. My Rust code (which I'm referring to as Rustbustion) can compile on Linux or Mac with the Mac implementation being super simple. My Raspberry Pi code can talk to the thermometer, pull data, and upload it to S3. We are getting there!
My next post will about the little web server I wrote to pull the S3 data, the little interface I put together for it, and anything else that might come up. Of course feel free to check out the github repo as I'm writing this after I've pushed the code already.